Comment fonctionne un moteur de recherche?
Le web est constitué de plusieurs milliards de documents. Les internautes peuvent utiliser les moteurs de recherche pour trouver une ressource parmi cette jungle. La méthodologie utilisée par les moteurs de recherche est présenté d'une manière simple dans cet article.
Comment un moteur de recherche trouve les pages web?

Les moteurs de recherche (Google, Yahoo ou encore Bing) utilisent des robots, intitulés crawlers ou spiders dans la langue de Shakespeare. Ces robots sont des processus informatiques qui se contentent de lire une page web, d'y extraire les liens et d'aller visiter ultérieurement les liens trouvés. En suivant les pages, de liens en liens, ces robots sont capables de visiter pratiquement tout le web.
Malgré la puissance de ces crawlers, il y a certaines limitations:
- Il n'est normalement pas possible pour ces robots de trouver une page orpheline (page qui ne reçoit aucun lien)
- Le web étant si grand, les robots ne peuvent tout indexer et mettre à jour rapidement. Selon le moteur de recherche et la méthodologie qui lui est associé, une page peut être revisitée quelques heures après sa publication ou plusieurs mois après
A titre d'exemple, le moteur de recherche Google utilise un principe simple lorsqu'il découvre des nouvelles pages: s'il découvre une page lambda il l'a met dans une file d'attente et ira la visiter quand il aura le temps. Si ce même robot trouve un autre lien vers cette page, alors il met l'adresse de la page dans une liste d'attente prioritaire. Le robot se contente ensuite de visiter les pages prioritaires et les autres pages ne sont visitées qu'ultérieurement lorsque le spider à un peu plus de temps.
En vue de ces raisons, il est possible de faire un petit constat:
- Un site qui ne reçoit aucun lien sera plus difficilement trouvé par les moteurs de recherche
- Les modifications apportées sur un site web ne sont pas répertoriées instantanément sur les résultats d'un moteur de recherche. Il faut alors une autre visite des robots (peut-être une semaine plus tard)
Comment les pages sont sauvegardées?

Une fois qu'un robot à visité une page, il va l'enregistrer dans des énormes data-center. Ces derniers enregistrent ainsi des milliards et des milliards de pages web.
L'étape suivante consiste pour le moteur de recherche d'extraire les informations et des les indexer. Sachant que les robots ne sont que ces processus information, ils sont en général capables de lire uniquement le contenu textuel. Il est compliqué et fastidieux pour un processus informatique d'essayer de lire le contenu textuel incluant sur une image ou de reconnaitre les mots d'une bande son.
Le processus qui consister à enregistrer les informations dans un index est fort simple à comprendre. En langage informatique, un index est similaire au principe des index utilisé dans les livres. L'index recense les mots et l'endroit où ils sont présents. Par exemple, l'index peut indiquer que le mot "bonjour" est utilisé sur les pages 12, 34, 35 et 57. Cela sera ultérieurement utilisé pour gagner du temps lorsqu'un visiteur effectuera un requête.
Les index ne listent cependant pas tous les mots. Les skip words (ou "stop words) désignent des petits mots très souvent utilisés, qui ne sont pas indexé en raison de leur utilisation très commune. Parmi ces petits mots, il y a par exemple: "le", "la", "du", "à" et plusieurs autres du même genre.
Il est aussi important de savoir que le moteur de recherche Google possède deux index. L'un est consacré aux pages principales de confiance et le second est un index supplémentaire concernant des pages avec un contenu dupliqué, un contenu insignifiant, un contenu peut-être de très mauvaise qualité (possibilité que ce soit du spam) ou diverses raisons. Sans nul doute, ce sont les pages présentes sur l'index principal qui seront les plus visibles dans les résultats de recherche.
Pour finir, il est judicieux de savoir que toutes les pages ne seront pas sauvegardées. Certaines pages provenant de site illégaux ou pratiquant de très mauvaises pratiques, seront tout simplement blacklistés. Dans ce cas de figure, un moteur de recherche mémorise l'adresse de la page (ou du site) pour l'ignorer s'il découvre un lien vers le site ultérieurement. Pour cette raison, il faut faire attention lors de l'achat d'un nom de domaine que ce nom de domaine ne soit pas "blacklisté".
Comment un engin de recherche classe les résultats?
Lorsqu'un internaute effectue une recherche, il y a souvent des millions de pages qui possèdent le mot recherché. Pour cette raison, les moteurs doivent classer les résultats par pertinence. Les utilisateurs d'un moteur de recherche doivent facilement trouver le résultat qui répondra à leurs attentes.
Il y a deux grands critères qui influent le classement des résultats: la pertinence de la page vis-à-vis des mots recherchés et la popularité de la page. Des centaines de critères peuvent être pris en compte, tous ne seront pas décrit, voici juste une petite liste de certains critères:
- Évaluer la pertinence: le mot-clé est-il présent dans le titre? dans l'URL? dans le contenu? Y'a t-il des synonymes du mot recherché dans le contenu? ...
- Évaluer la popularité: est-ce que la page reçoit beaucoup de liens? Ces liens proviennent-ils de pages elles-mêmes populaires? Les pages faisant des liens ont-elles la même thématique? Les sites qui font des liens vers cette page sont-il dans la même langue? Sont-ils des sites de confiance? ...
Malgré ces deux principaux facteurs influant sur les résultats, des critères alternatifs font leurs apparitions. Par exemple, le moteur de recherche Google base maintenant ses résultats selon la localité du visiteur et selon l'historique des précédentes recherches effectuées par l'internaute.
Pourquoi les pages de résultats sont si rapides?
Il y a quelques petites choses à savoir sur le fonctionnement d'un moteur de recherche lors d'une requête. La première chose à savoir c'est que le moteur de recherche ne cherche pas sur le web, mais cherche plutôt sur ce qui est connu des moteurs de recherche et indexé. Ensuite, le moteur de recherche utilise le principe des index. Pour utiliser une analogie, c'est comme s'il utilisait l'index d'un livre pour chercher les pages qui contiennent le(s) mot(s) recherchés.
Contrairement à une pensée commune, certains moteurs de recherche tel que Google, n'utilisent pas un super ordinateur. A la place, c'est un réseau de très nombreux ordinateurs à capacités normales qui est utilisé. Les performances sont beaucoup plus notables. Pour faire une analogie, c'est comme si Google demandait à un groupe de 20 personnes de regarder l'index d'un livre chacun. C'est plus efficace que de demander à une seul personne (aussi brillante soit-elle) de lire seul l'index de chacun des 20 livres.
Finalement, les moteurs de recherche ont une astuce secrète pour fournir des résultats encore plus rapide. Sachant que certaines requêtes sont très populaires (exemple: "Facebook", "Youtube", "Vidéo", "TV", "Jeux" ...), les moteurs préparent à l'avance les résultats. Ainsi, ils donnent directement les résultats sans nécessairement avoir à chercher dans l'index.
Comment un moteur de recherche gagne de l'argent?
La méthode la plus commune pour un moteur de recherche pour gagner de l'argent, consiste à afficher des résultats sponsorisés lors d'une recherche. Des sites web payent donc les moteurs pour que leur site soit en tête de certains résultats, mais uniquement dans la partie réservée aux résultats sponsorisés.
Le moteur de recherche Google affiche des annonces à droites des résultats de recherches dits naturels et parfois en haut des résultats, comme le montre la capture d'écran ci-jointe:
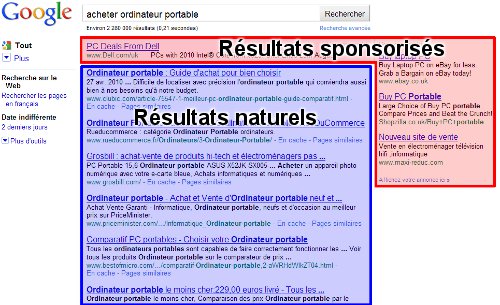
Résultats naturels et résultats sponsorisés sur Google
Comment améliorer la visibilité d'un site sur un moteur?
Il y a deux manières d'obtenir une bonne visibilité sur les moteurs de recherche. La première consiste à utiliser des méthodes de référencement naturel. Cela consiste à utiliser des méthodes de bonnes pratiques pour qu'un site obtienne un bon positionnement dans les résultats de recherche. Ces techniques mettent du temps à porter leurs fruits mais sont avantageuses sur le long terme.
La deuxième manière consiste à payer pour avoir une page dans les résultats sponsorisés. Pour le moteur de recherche Google, il faut utiliser le service Google AdWords. Le positionnement des annonces dans les résultats sponsorisés est basé sur un système d'enchère.
Il est également possible d'utiliser des méthodes de référencement dites black hat. Cela consiste à exploite les failles des algorithmes des moteurs de recherche pour tenter d'être bien placé dans les résultats de recherche. Ces techniques ne sont pas appréciées par les moteurs. Dès lors, si un moteur arrive à détecter une méthode de référencement black hat, il peut pénaliser le site (certains sites peuvent être blacklistés).
Article rédigé par Tony_ le 14/08/2010 à 20h28 dans la catégorie "Information" du site InfoWebMaster.fr.
